[UD ID Founds Series, cf. Bartlett on IC]
Ever since Dawkins’ Mt Improbable analogy, a common argument of design objectors has been that such complex designs as we see in life forms can “easily” be achieved incrementally, by steps within plausible reach of chance processes, that are then stamped in by success, i.e. by hill-climbing. Success, measured by reproductive advantage and what used to be called “survival of the fittest.”
[Added, Oct 15, given a distractive strawmannisation problem in the thread of discussion: NB: The wide context in view, plainly, is the Dawkins Mt Improbable type hill climbing, which is broader than but related to particular algorithms that bear that label.]
Weasel’s “cumulative selection” algorithm (c. 1986/7) was the classic — and deeply flawed, even outright misleading — illustration of Dawkinsian evolutionary hill-climbing.
To stir fresh thought and break out of the all too common stale and predictable exchanges over such algorithms, let’s put on the table a key remark by Stanley and Lehman, in promoting their particular spin on evolutionary algorithms, Novelty Search:
. . . evolutionary search is usually driven by measuring how close the current candidate solution is to the objective. [ –> Metrics include ratio, interval, ordinal and nominal scales; this being at least ordinal] That measure then determines whether the candidate is rewarded (i.e. whether it will have offspring) or discarded. [ –> i.e. if further moderate variation does not improve, you have now reached the local peak after hill-climbing . . . ] In contrast, novelty search [which they propose] never measures progress at all. Rather, it simply rewards those individuals that are different.
Instead of aiming for the objective, novelty search looks for novelty; surprisingly, sometimes not looking for the goal in this way leads to finding the goal [–> notice, an admission of goal- directedness . . . ] more quickly and consistently. While it may sound strange, in some problems ignoring the goal outperforms looking for it. The reason for this phenomenon is that sometimes the intermediate steps to the goal do not resemble the goal itself. John Stuart Mill termed this source of confusion the “like-causes-like” fallacy. In such situations, rewarding resemblance to the goal does not respect the intermediate steps that lead to the goal, often causing search to fail . . . .
Although it is effective for solving some deceptive problems, novelty search is not just another approach to solving problems. A more general inspiration for novelty search is to create a better abstraction of how natural evolution discovers complexity. An ambitious goal of such research is to find an algorithm that can create an “explosion” of interesting complexity reminiscent of that found in natural evolution.
While we often assume that complexity growth in natural evolution is mostly a consequence of selection pressure from adaptive competition (i.e. the pressure for an organism to be better than its peers), biologists have shown that sometimes selection pressure can in fact inhibit innovation in evolution. Perhaps complexity in nature is not the result of optimizing fitness, but instead a byproduct of evolution’s drive to discover novel ways of life.
While their own spin is not without its particular problems in promoting their own school of thought — there is an unquestioned matter of factness about evolution doing this that is but little warranted by actual observed empirical facts at body-plan origins level, and it is by no means a given that “evolution” will reward mere novelty — some pretty serious admissions against interest are made.
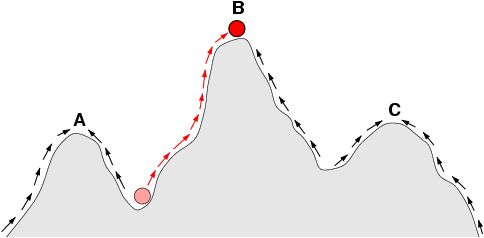
Now, since this “mysteriously” seems to be controversial in the comment thread below, courtesy Wikipedia, let us add [Sat, Oct 15] a look at a “typical” topology of a fitness landscape, noticing how there is an uphill slope all around it, i.e. we are looking at islands of function that lead uphill to local maxima by hill-climbing in the broad, Dawkinsian, cumulative steps up Mt Improbable sense:
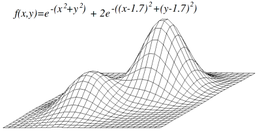
Now, too, right from the opening remarks in the clip, Stanley and Lehman acknowledge how targetted searches dominate the evolutionary algorithm field, a point often hotly denied by advocates of GA’s as good models of how evolution is said to have happened:
. . . evolutionary search is usually driven by measuring how close the current candidate solution is to the objective. [ –> i.e. if further moderate variation does not improve, you have now reached the local peak after hill-climbing . . . ] That measure [ –> Metrics include ratio, interval, ordinal and nominal scales; this being at least ordinal] then determines whether the candidate is rewarded (i.e. whether it will have offspring) or discarded . . . . in some problems ignoring the goal outperforms looking for it. The reason for this phenomenon is that sometimes the intermediate steps to the goal do not resemble the goal itself. John Stuart Mill termed this source of confusion the “like-causes-like” fallacy. In such situations, rewarding resemblance to the goal does not respect the intermediate steps that lead to the goal, often causing search to fail
We should also explicitly note what should be obvious, but is obviously not to many: nice, trend-based uphill climbing in a situation where the authors of a program have loaded in a function with trends and peaks, is built-in goal-seeking behaviour (as the first illustration above shows).
Similarly, we see how the underlying assumption of a smoothly progressive Hill- Climbing trend to the goal is highly misleading in a world where there may be irreducibly complex outcomes, where the components, separately do not move you to the target of performance, but when suitably joined together we see an emergent result not predictable from projecting trend lines. (Of course, Stanley and Lehman tiptoe quietly around explicitly naming that explosive concept. But that is exactly what is at work in the case where “intermediate steps” do not lead to a goal: it is not “steps” but components that as a core cluster must all be present and must be organised in the right pattern to work together, to have the resulting function. Even something as common as a sentence tends to exhibit this pattern, and algorithm-implementing software is a special case of that. Think about how often a single error can trigger failure.)
The incrementalist claim, then, is by no means a sure thing to be presented with the usual ever so confident, breezily assured assertions that we hear ever so often. For, the fallacy of confident manner lurks.
Secondly, let us also note how the incrementalist objection actually implies a key admission or two.
For one, we can see that apparent design is a recognised fact of the world of life, i.e. as Dawkins acknowledges in opening remarks of his The Blind Watchmaker, 1986; as, Proponentist has raised in the current Free Thinker UD thread:
Elsewhere, in River out of Eden (1995), as Proponentist also highlights, Dawkins adds:
These two remarks underscore a point objectors to design thought are often loathe to acknowledge: namely, that Design Scientist, William Dembski is fundamentally right: significant increments in functionally specific complexity beyond a threshold by blind chance and/or mechanical necessity, are so improbable as to be effectively operationally impossible on the gamut of our observed universe.
Similarly, as Proponentist goes on to ask:
How does Mr. Dawkins know that something gives the appearance of design? Can his statement be tested scientifically?
Obviously, if Mr. Dawkins is correct, then he is talking about “evidence that design can be observed in nature” . . . . You can either observe design (of some kind) or not. If you can observe it, then you already distinguish it from non-design.
This is already a key point: as a routine matter, we recognise that — on a wealth of experience and observation — complex, functionally specific arrangements of parts towards a goal, are best explained as intentionally and intelligently chosen, composed or directed. That is, as designed.

But, the onward Darwinist idea is that every instance of claimed design in the world of life can be reduced to a process of incremental changes that gradually accumulate from some primitive original self-replicating organism (and beyond that, original self replicating molecule or molecular cluster), through the iconic Darwinian tree of life — already, a consciously ironic switcheroo on the Biblical Tree of Life in Genesis and Revelation.
So, already, through the battling cultural icons, we know that much more than simply science is at stake here.
So also, we know to be on special guard against questionable worldview assumptions such as those promoted by Lewontin and so many others.
Now, too, Design objector Petrushka, has thrown down a rhetorical gauntlet in the current UD Freethinker thread:
One can accept the inference that a complex system didn’t arise in one step by chance without saying anything specific about its history.
The argument is about the specific history, not whether 500 or whatever bits of code arose purely by chance . . . . The word “design,” whether apparent or otherwise means nothing. It’s a smoke screen. The issue is whether known mechanisms can account for the history.
Words like “smoke screen” imply an unfortunate accusation of deception, and put a fairly stiff burden of proof on those who use them. Which — on fair comment — has not been met, and cannot be soundly met, as the accusation is simply false.
Similarly “purely by chance” is a strawman caricature.
One, that ducks the observed fact that there are exactly two observed sources of highly contingent outcomes: chance [e.g. what would happen by tossing a tray of dice] and intelligent arrangement [e.g. arranging the same tray of dice in a specific pattern]. Mechanical necessity [e.g. a dropped heavy object reliably falls at 9.8 m/s2 near earth’s surface] is not a source of high contingency. So, in the combination of blind chance and mechanical necessity, the highly contingent outcomes would be coming from the chance component.
Nevertheless, we need to show that “design” is most definitely not a meaningless or utterly confusing term, generally or in the context of the world of life.
That’s why I replied:
Design is itself a known, empirically observed, causal mechanism. Its specific methods may vary, but designs are as familiar as the composition of the above clipped sentences of ASCII text: purposeful arrangement of parts, towards a goal, and typically manifesting a coherence in light of that purpose.
The arrangement of 151 ASCII 128-state characters above as clipped [from the first part of the cite from Petrushka], is one of 1.544*10^318 possibilities for that many ASCII characters.
The Planck Time Quantum State resources of the observed universe, across its thermodynamically credible lifespan, 50 million times the time since the usual date for the big bang, could not take up as many as 1 in 10^150 of those possibilities. Translated into a one-straw sized sample, millions of cosmi comparable to the observed universe could be lurking in a haystack that big, and yet, a single cosmos full of PTQS’s sized sample would overwhelmingly be only likely to pick up a straw. (And, it takes about 10^30 PTQS’s for the fastest chemical interactions.)
It is indisputable that a coherent, contextually responsive sequence of ASCII characters in English — a definable zone of interest T, from which your case E above comes — is a tiny and unrepresentative sample of the space of possibilities for 151 ASCII characters, W.
We habitually and routinely know of just one cause that can credibly account for such a purposeful arrangement of ASCII characters in a string structure that fits into T: design. The other main known causal factors at this level — chance and/or necessity, without intelligent intervention — predictably would only throw out gibberish in creating strings of that length, even if you were to convert millions of cosmi the scope of our own observed one, into monkeys and world processors, with forests, banana plantations etc to support them.
In short, there is good reason to see that design is a true causal factor. One, rooted in intelligence and purpose, that makes purposeful arrangements of parts; which are often recognisable from the resulting functional specificity in the field of possibilities, joined to the degree of complexity involved.
As a practical matter, 500 – 1,000 bits of information-carrying capacity, is a good enough threshold for the relevant degree of complexity. Or, using the simplified chi metric at the lower end of that range:
Chi_500 = I*S – 500, in bits beyond the solar system threshold.
So, when we see the manifestation of FSCO/I, we do have a known, adequate mechanism, and ONLY one known, adequate mechanism. Design.
That is why FSCO/I is so good as an empirically detectable sign of design, even when we do not otherwise know the causal history of origin.
{Added: this can be expressed through the explanatory filter, applied per aspect of a phenomenon or process, allowing individual aspects best explained by mechanical necessity, chance and intelligence to be separated out, step by step in our analysis:

Do you really mean to demand of us that we believe that design by an intelligence with a purpose is not a known causal mechanism? If so, what then accounts for the PC you are using? The car you may drive, or the house or apartment etc. that you may live in?
Do you see how you have reduced your view to blatant, selectively hyperskeptical absurdity?
And, of course, the set of proteins and DNA for even the simplest living systems, is well beyond the FSCI threshold. 100,000 – 1 mn+ DNA bases is well beyond 1,000 bits of information carrying capacity.
Yes, that points to design as the best explanation of living systems in light of the known cause of FSCO/I. What’s new about that or outside the range of views of qualified and even eminent scientists across time and today?
Similarly, the incrementalist mechanism of blind chance and mechanical necessity through trial and error/success thesis has some stiff challenges to meet:
. . . the usual cases of claimed observed incremental creation of novel info beyond the FSCI threshold, as a general rule boil down to:
(a) targetted movements within an island of function, where the implicit, designed in information of a so-called fitness function of a well behaved type — trends help rather than lead to traps — is allowed to emerge step by step. (Genetic Algorithms are a classic of this.)
(b) The focus is made on a small part of the process, much like how if a monkey were to indeed type out a Shakespearean sonnet by random typing, there would now be a major search challenge to identify that this has happened, i.e. to find the case in the field of failed trials.
(c) We are discussing relatively minor adaptations of known functions, well beyond the FSCI threshold — hybridisation, or breaking down based on small mutations etc. For instance, antibiotic resistance, from a Design Theory view, must be recognised in light of the prior question: how do we get to a functioning bacterium based on coded DNA? (Somehow, the circularity of evolutionary materialism leads ever so many to fail to see that ability to adapt to niches and changes may well be a part of a robust design!)
(d) We see a gross exaggeration of the degree and kind of change involved, e.g. copying of existing info is not creation of new FSCI. A small change in a regulatory component of the genome that shifts how a gene is expressed, is a small change, not a jump in FSCI. Insertion of a viral DNA segment is creation of a copy and transfer to a new context, not innovation of information. Etc.
(e) We see circularity, e.g. the viral DNA is assumed to be of chance origin.
And so forth.
In short, some big questions were silently being begged all along in the discussions and promotions of genetic algorithms as reasonable analogies for body plan level evolution, and in the assertions that blind chance variations plus culling out of the less reproductively successful can account for complex functional organisation and associated information as we see in cell based life.
Let us therefore ask a key question about the state of actual observed evidence: has the suggested gradual emergence of life from an organic chemical stew in some warm little pond or a deep-sea volcano vent or a comet core or a moon of Jupiter, etc, been empirically warranted?
Nope, as the following recent exchange between Orgel and Shapiro will directly confirm — after eighty years of serious trying to substantiate Darwin’s warm little pond suggestion, neither the metabolism first nor the Genes/RNA first approaches work or are even promising:
Of course, in the three or so years since (and despite occasional declarations to the contrary; whether in this blog or elsewhere . . . ), the case has simply not got any better. [If you doubt me, simply look for the Nobel Prize that has been awarded for the resolution of the OOL challenge in the past few years. To save time, let me give the answer: there simply is none.]
Bottomline: the proposed Darwinian Tree of Life has no tap-root.
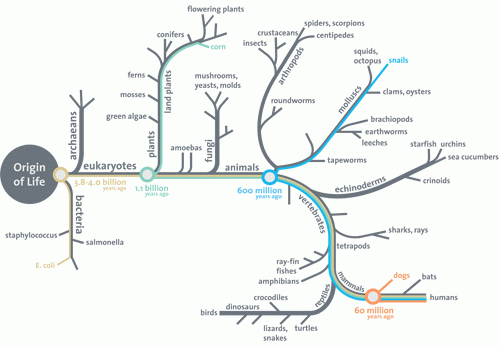
No roots, no shoots, and no branches.