(NB: ID Foundations Series, so far: 1, 2, 3.)
In a recent comment on the ID Foundations 3 discussion thread, occasional UD commenter LastYearOn [henceforth LYO], remarked:
Behe is implicitly assuming that natural processes cannot explain human technology. However natural processes do explain technology, by explaining humans. We may think of computers as somehow distinct from objects that formed from the direct result of natural process. And in important ways they are. But that doesn’t mean that they aren’t ultimately explainable naturally. Behe’s argument is therefore circular.
Think of it this way. In certain ways nature is prone to organization. From cells to multicellular organisms to humans. Computers are just the latest example.
In essence, LYO is arguing — yea, even, confidently assuming — that since nature has the capacity to spontaneously generate designers through evolutionary means, then technology and signs of design reduce to blind forces and circumstances of chance plus necessity in action. Thus, when we behold, say a ribosome in action —
![]()
Fig. A: The Ribosome in action in protein translation, assembling (and then completing) a protein step by step [= algorithmically] based on the sequence of three-letter codons in the mRNA tape and using tRNA’s as amino acid “taxis” and position-arm tool-tips, implementing a key part of a von Neumann-type self replicator . (Courtesy, Wikipedia.)
{kind=link}
___________________
. . . we should not think, digitally coded, step by step algorithmic process, so on signs of design, design. Instead, LYO and other evolutionary materialists argue that we should think: here is an example of the power of undirected chance plus necessity to spontaneously create a complex functional entity that is the basis for designers as we observe them, humans.
So, on the evolutionary materialistic view, the triad of explanatory causes, necessity, chance, art, collapses into the first two. Thus, signs of design such as specified complexity and associated highly specific functional organisation — including that functional organisation that happens to be irreducibly complex — reduce to being evidences of the power of chance and necessity in action!
Voila, design is finished as an explanation of origins!
But is this assumption or assertion credible?
No . . . it fallaciously begs the question of the underlying power of chance plus necessity, thus setting up the significance of the issue of specified complexity as an empirically reliable sign of design. No great surprise there. But, the issue also opens the door to a foundational understanding of the other hotly contested core ID concept, specified complexity.
First, let us define, using the ISCID summary (which is based on Dembski’s work):
Specified complexity consists of two important components, both of which are essential for making reliable design inferences. The first component is the criterion of complexity or improbability. In order for an event to meet the standards of Dembski’s theoretical notion of specified complexity, the probability of its happening must be lower than the Universal Probability Bound which Dembski sets at one chance in 10^150 possibilities.
The second component in the notion of specified complexity is the criterion of specificity. The idea behind specificity is that not only must an event be unlikely (complex), it must also conform to an independently given, detachable pattern. Specification is like drawing a target on a wall and then shooting the arrow. Without the specification criterion, we’d be shooting the arrow and then drawing the target around it after the fact.
Immediately, however, we must point out that the specified complexity (and linked functional organisation) concept is not an abstract innovation of Dembski and other leaders of the design theory movement. That movement emerged in the early 1990’s in response to developments and thoughts on origins, especially origin of life, in the 1970’s and 80’s. In that context, the specified complexity concept dates to that earlier era and is in fact one of the key triggers for the emergence of design theory.
For, the early ID thinkers and scientists (starting with Thaxton, Bradley and Olsen [TBO] in The Mystery of Life’s Origin [TMLO — download (fat!) here], the first technical level ID book, 1984) were asking: what — on our consistent experience and observation — best explains specified complexity and associated functional organisation?
A world of technology was answering: simple — intelligence, purpose and design.
To see the reason for that answer, let us go back to the originators of the concept of specified complexity and how they understood its significance, i.e. origin of life researchers Orgel and Wicken (with a glance back to Polanyi):
Orgel, 1973:
In brief, living organisms are distinguished by their specified complexity. Crystals are usually taken as the prototypes of simple well-specified structures, because they consist of a very large number of identical molecules packed together in a uniform way. Lumps of granite or random mixtures of polymers are examples of structures that are complex but not specified. The crystals fail to qualify as living because they lack complexity; the mixtures of polymers fail to qualify because they lack specificity. [Source: L.E. Orgel, 1973. The Origins of Life. New York: John Wiley, p. 189. Emphases added. Crystals, of course, would by extension include snow crystals, and order enfolds cases such as vortexes, up to and including hurricanes etc. Cf. here.]
Wicken, 1979:
‘Organized’ systems are to be carefully distinguished from ‘ordered’ systems. Neither kind of system is ‘random,’ but whereas ordered systems are generated according to simple algorithms [i.e. “simple” force laws acting on objects starting from arbitrary and common- place initial conditions] and therefore lack complexity, organized systems must be assembled element by element according to an [originally . . . ] external ‘wiring diagram’ with a high information content . . . Organization, then, is functional complexity and carries information. It is non-random by design or by selection, rather than by the a priori necessity of crystallographic ‘order.’ [“The Generation of Complexity in Evolution: A Thermodynamic and Information-Theoretical Discussion,” Journal of Theoretical Biology, 77 (April 1979): p. 353, of pp. 349-65. (Emphases and notes added. Nb: “originally” is added to highlight that for self-replicating systems, the blue print can be built-in.)]
Even earlier, as TBO summarised in TMLO, Polanyi had observed in the 1960’s that the distinguishing feature of living systems is [we may safely add: functionally organised] complexity rather than order.
TBO, in ch 8 of TMLO, also give a useful illustrative example that helps us distinguish the three concepts:
Three sets of letter arrangements show nicely the difference between order and complexity in relation to information:
[Type] 1. An ordered (periodic) and therefore specified arrangement:
THE END THE END THE END THE END
Example: Nylon, or a crystal.
[NOTE: Here we use “THE END” even though there is no reason to suspect that nylon or a crystal would carry even this much information. Our point, of course, is that even if they did, the bit of information would be drowned in a sea of redundancy].
[Type] 2. A complex (aperiodic) unspecified arrangement:
AGDCBFE GBCAFED ACEDFBG
Example: Random polymers (polypeptides).
[Type] 3. A complex (aperiodic) specified arrangement:
THIS SEQUENCE OF LETTERS CONTAINS A MESSAGE!
Example: DNA, protein.
Yockey7 and Wicken5 develop the same distinction, that “order” is a statistical concept referring to regularity such as could might characterize a series of digits in a number, or the ions of an inorganic crystal. On the other hand, “organization” refers to physical systems and the specific set of spatio-temporal and functional relationships among their parts. Yockey and Wicken note that informational macromolecules have a low degree of order but a high degree of specified complexity. In short, the redundant order of crystals cannot give rise to specified complexity of the kind or magnitude found in biological organization; attempts to relate the two have little future. [Emphases & parentheses added. “Wickens” corrected. (Pardon the typographically ugly multiple emphases; given the many contentions and conflicting claims, it can be hard to see just what is being said.)]
In short, the Type 3 relationship among parts in a whole — i.e. meaningful, functional organisation manifesting specified complexity and associated information — is what is to be explained at the root of the tree of life. And, from our world of experience and habitual common sense, undirected chance and/or necessity are not credible causal factors for such.
A transformed version of a classic example used to make it seem plausible that given enough time and resources, chance can duplicate anything that intelligence is usually credited for, will help us see why:
a –> Imagine that our whole observable universe [~10^80 atoms] was suddenly transformed into planetary systems having terrestrial, earth-like planets occupied by monkeys sitting at keyboards, with typewriters [let us make these ASCII typewriters, for convenience, without loss of generality] and paper, supported by banana plantations, forests and factories to keep things in working order, and rail road networks tying all together:

Fig. B: A monkey at the keyboard. (Courtesy Wiki, public domain)
{kind=link}
b –> These multiplied trillions and trillions of diligent monkeys spend their time banging away at the keyboards at random, say 10 strokes per second (better than 60 average length English “words” per minute, were their strokes to make sense).
c –> The classic argument is that — on simple mathematics of having enough resources to exhaust the possibilities for combinations of keystrokes — at length, they would produce the entire Shakespearean corpus, simply by virtue of random keystrokes; so chance, if given enough time and resources will produce anything that we see designers doing.
d –> In fact, given the significance of the Abel universal plausibility bound, advocates of this idea are wrong, and Cicero is right:
Is it possible for any man to behold these things, and yet imagine that certain solid and individual bodies move by their natural force and gravitation, and that a world so beautifully adorned was made by their fortuitous concourse? He who believes this may as well believe that if a great quantity of the one-and-twenty letters, composed either of gold or any other matter, were thrown upon the ground, they would fall into such order as legibly to form the Annals of Ennius. I doubt whether fortune could make a single verse of them. How, therefore, can these people assert that the world was made by the fortuitous concourse of atoms, which have no color, no quality—which the Greeks call [poiotes], no sense? [Cicero, THE NATURE OF THE GODS BK II Ch XXXVII, C1 BC, as trans Yonge (Harper & Bros., 1877), pp. 289 – 90.]
e –> Q: How so? A: Take the 10^80 or so atoms of our observed cosmos, and allow them to change state every Planck time [rounded down to 10^-45 s], for the thermodynamically credible lifespan of the said cosmos [~ 10^25 s or 50 mn times the estimated time since the usual date for the big bang]. That gives us 10^150 possible Planck-time states to search a configuration space, whether by monkeys at keyboards or any other physical means. But, just 1,000 bits, where 1 bit is one yes/no decision, specifies such a space of 2^1,000 = 1.07 * 10^301 states. Which means that he whole observed universe for its lifespan would not sample more than 1 in 10^150 of the possible states, so small a fraction that once the functionally organised states that the scope of search relative to the scope of the space is a practical zero. Lucky noise, whether by monkeys at keyboards or otherwise, is not a credible explanatory cause for functionally specific, complex organisation and related information [FSCO/I].
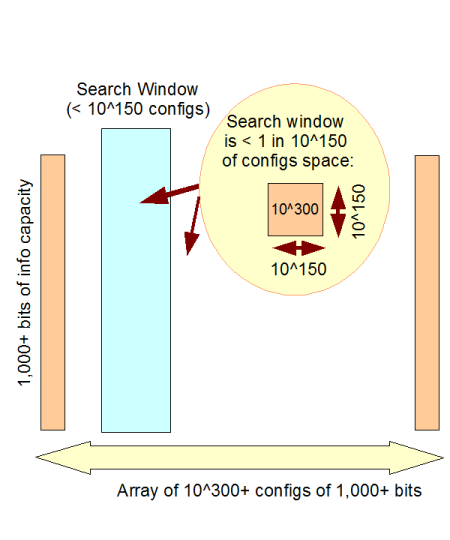
Fig. C: The Cosmic search window, showing how a search on the scope of our observed cosmos could not capture more than 1 in 10^150 of the possible configurations for 1,000 bits.
f –> In short, Wiki’s remark early in its article on the monkeys at keyboards “theorem” is technically true but materially misleading, when it says:
The infinite monkey theorem states that a monkey hitting keys at random on a typewriter keyboard for an infinite amount of time will almost surely type a given text, such as the complete works of William Shakespeare.
In this context, “almost surely” is a mathematical term with a precise meaning, and the “monkey” is not an actual monkey, but a metaphor for an abstract device that produces a random sequence of letters ad infinitum. The theorem illustrates the perils of reasoning about infinity by imagining a vast but finite number, and vice versa. The probability of a monkey exactly typing a complete work such as Shakespeare‘s Hamlet is so tiny that the chance of it occurring during a period of time of the order of the age of the universe is minuscule, but not zero.
g –> But in fact, it is a practical zero, the same sort of practical zero that is relied upon to establish the statistical form of the second law of thermodynamics [cf article 2 in this series]. Ironically, deep in the article, the usual Wiki anonymous collective of authors does in fact make the corrective point, drawing on a classic edition of a famous short textbook in Statistical Thermodynamics:
The text of Hamlet contains approximately 130,000 letters.[note 3] Thus there is a probability of one in 3.4 × 10183,946 to get the text right at the first trial. The average number of letters that needs to be typed until the text appears is also 3.4 × 10183,946,[note 4] or including punctuation, 4.4 × 10360,783.[note 5]
Even if the observable universe were filled with monkeys typing from now until the heat death of the universe, their total probability to produce a single instance of Hamlet would still be less than one in 10183,800. As Kittel and Kroemer put it, “The probability of Hamlet is therefore zero in any operational sense of an event…”, and the statement that the monkeys must eventually succeed “gives a misleading conclusion about very, very large numbers.” This is from their textbook on thermodynamics, the field whose statistical foundations motivated the first known expositions of typing monkeys.[3]
h –> The next round of the exchange is to hop up to the multiverse, where in effect the available search resources are multiplied by a speculated quasi-infinite universe as a whole that has in it effectively infinitely many sub-cosmi, including one that got lucky. Namely our own.
i –> This is more subtly flawed, in two key ways. First, there is no empirical evidence for such a quasi-infinite multiverse, so this is an exercise in speculative metaphysics, not inductively based, scientific inference. Second, the fine-tuning associated with the “cosmos bakery” such a multiverse requires to allow it to support creation of a distribution of sub-cosmi that searches our very narrow life-permitting range closely enough to credibly capture our own fine-tuned case, is itself “suspicious.” That is, the multiverse concept itself points to design as best explanation, once we exist in our world.
j –> The multiverse proposal, in short, is a case of an ad hoc metaphysical speculation designed to save the phenomena for a view that is in trouble on other grounds. The question of question-begging to foreclose a serious level playing field inference to best explanation across live options, rears its head.
k –> The only thing that would save the lucky noise inference, is a demonstration that a cosmos-generating intelligence is — logically — impossible. And such is not forthcoming.
In short, the basic inference to design on observing specified complexity and/or associated functionally specific, complex organisation and information [FSCO/I], is inductively strong. For, we routinely observe such FSCO/I being made by designers, and we only observe it coming from such. And, we can back it up with an analysis on the isolation of islands of function in a configuration space, once we are dealing with at least 500 – 1,000 or so functionally specific bits.
In turn, the metric just introduced, is actually quite familiar: the bits we routinely use in IT contexts are functional and specific — a bit of noise would easily disrupt function.
So, we have a commonplace, basic metric for our simplest metric and threshold for “sufficiently complex” for inferring to design on seeing FSCO/I. (NB: More complex metrics are discussed here.)
The debates over more sophisticated metrics and thresholds, especially given the above, make no material difference to the above conclusion.
But, given their contentiousness, it may be useful to cut to the chase and speak about [especially, digitally coded] functionally specific, complex information and related organisation: FSCI, or FSCO/I.
In the end, debates over models and metrics or abbreviations, simply distract attention from a fairly straightforward and hard to confute inductive inference from observed pattern of signs, FSCO/I and its reasonably — empirically, provisionally and inductively — inferred meaning, design as most credible causal process. END
_______________
PS: DV, [d]FSCI and FSCO/I will come up next in the ongoing series . . .