(Series on Front-loading continues, here)
As we continue the ID Foundations series, it will be necessary to reflect on a fairly wide range of topics, more than any one person can cover. So, when the opportunity came up to put Front-Loading on the table from a knowledgeable advocate of it, Genomicus, I asked him if he would be so kind as to submit such a post.
He graciously agreed, and so, please find the below for our initial reflections; with parts B and C (and maybe, more? please, please, sir . . . 😆 ) to follow shortly, DV:
____________________
>> Critics of intelligent design (ID) often argue that ID does not offer any testable biological hypotheses. Indeed, often times ID proponents seem to be content with simply attacking Darwinian theory, while not offering a testable hypothesis of their own. There’s no problem with pointing out flaws in a given theory, of course, but I think it’s time that ID proponents (myself included) begin to seriously develop a robust, testable design hypothesis in biology, and devote much of their energy to doing so. To quote from Intelligent design: The next decade, an Uncommon Descent article:
“As for the next decade, with luck, we are reaching the point where it’s safe to test design hypotheses, in the sense that many might fail and a few succeed. That’s the usual way with any endeavour in science, of course.”
I more than agree with that.
And so, in the spirit of developing a robust ID hypothesis in biology, I’ll be discussing the idea of front-loading, an inherently ID hypothesis.
What is the front-loading hypothesis? As far as I know, Mike Gene first proposed the front-loading hypothesis, and formally presented it in his book, The Design Matrix. On page 147 of The Design Matrix, we find a succinct definition of front-loading:
“Front-loading is the investment of a significant amount of information at the initial stage of evolution (the first life forms) whereby this information shapes and constrains subsequent evolution through its dissipation. This is not to say that every aspect of evolution is pre-programmed and determined. It merely means that life was built to evolve with tendencies as a consequence of carefully chosen initial states in combination with the way evolution works.”
In short, this ID hypothesis proposes that the earth was, at some point in its history, seeded with unicellular organisms that had the necessary genomic information to shape future evolution. Necessarily, this genomic information was designed into their genomes. Also note that under this hypothesis, the genetic code was efficient from the start, since it was, again, intelligently designed by some mind or minds. Further, the proof-reading machinery of the cell, the transcription machinery, etc., would have been present with the genetic code at the dawn of life because the first life forms on earth would have been far more complex than the simple proto-life forms envisioned by opponents of ID. To quote from The Design Matrix again, front-loading is “using evolution to carry out design objectives.”
To be sure, the front-loading hypothesis is not consistent with the non-teleological view that intelligence was never involved with the origin of the genetic code, or the origin of the molecular machinery in prokaryotes, etc.
This is a tantalizing hypothesis, and if positive evidence was advanced in its favor, then this would be positive evidence that teleology has played a role in the history of life on earth. The question of “what was front-loaded” is an interesting one, and is a good research question. Suffice it to say that multicellular life, vertebrates, plants, and animals were probably front-loaded.
What front-loading is not
Front-loading does not propose that the initial life forms contained a massive amount of genes/genomic information. It does not propose that the first cells carried every single gene that we find throughout life. Nor does it propose that every single aspect of evolution was front-loaded. There is also the common misconception that front-loading entails the first cells carrying around genes that are turned off, and then suddenly they get turned on. This could be a feasible mechanism in isolated cases, but on the whole it suffers from the problem that genes that are turned off are likely to accumulate mutations that simply destroy the original gene sequence. This problem could be countered, I suppose, by overlapping genes (although overlapping genes aren’t nearly as pervasive in prokaryotes as in eukaryotes), and this is one area of the front-loading hypothesis that can be researched. Nevertheless, on the whole, front-loading most likely was not carried out by simply turning genes on and off.
Testable predictions of the front-loading hypothesis
The cool thing about the ID hypothesis of front-loading is that it’s testable in a very real sense, meaning we can actually do some bioinformatics analyses to test its predictions. What are some of the predictions it makes? Let’s consider a couple of them, outlined below.
- Firstly, the front-loading hypothesis predicts that important genes in multicellular life forms will share deep homology with genes in prokaryotes. However, one might object that Darwinian evolution also predicts this. However, from a front-loading perspective, we can go a step further and predict that genes that really aren’t that important to multicellular life forms (but are found in them nevertheless) will generally not share as extensive homology with prokaryote genes.
- With regards to the next prediction I will discuss, we will go very molecular, so hang on tightly. In eukaryotes, there are certain proteins that are extremely important. For example, tubulin is an important component of cilia; actin plays a major role in the cytoskeleton and is also found in sarcomeres (along with myosin), a major structure in muscle cells; and the list could go on. How could such proteins be front-loaded? Of course, with some of these proteins they could be designed into the initial life forms, but some of them are specific to eukaryotes, and for a reason: they don’t function that well in a prokaryotic context. For these proteins, how would a designer front-load them? Let’s say X is the protein we want to front-load. How do we go about doing this? Well, firstly, we can design a protein, Y, that has a very similar fold to X, the future protein we want to front-load. Thus, a protein with similar properties to X can be designed into the initial life forms. But what is preventing random mutations from basically destroying the sequence identity of Y, over time, such that the original fold/sequence identity of Y is lost? To counter this, Y can also be given a very important function so that its sequence identity will be well conserved.
Thus, we can make this prediction from a front-loading perspective: proteins that are very important to eukaryotes, and specific to them, will share deep homology (either structurally or in sequence similarity) with prokaryotic proteins, and importantly, that these prokaryotic proteins will be more conserved in sequence identity than the average prokaryotic protein.
Darwinian evolution only predicts the first part of that: it doesn’t predict that part that is in bold text. This is a testable prediction made exclusively by the front-loading hypothesis.
- The front-loading hypothesis also predicts that the earliest life forms on earth were quite complex, complete with ATP synthases, sophisticated proof-reading machinery, and the like. Figure:
- Figure: The front-loading hypothesis predicts that the genetic code in the first life forms was as optimized as it is today. It thus predicts that we will not find any less optimized genetic code at the root of the tree of life. Image from CUNY as linked, per fair use. [WP will not pass a link in a caption, KF]
Thus, we can see that the front-loading hypothesis is indeed testable, and so the claim that ID offers no testable hypotheses is simply not true.
Research Questions
Another neat thing about the front-loading hypothesis is that there are a number of research questions we can ask with regards to the front-loading hypothesis.
I have already mentioned the question of “what was front-loaded,” but we can go deeper than that. Below are some research questions generated by the front-loading hypothesis: research questions we can investigate to further understand biological reality. In another essay, I’ll be exploring these rather
interesting research questions (for example: was the bacterial flagellum front-loaded or designed at the dawn of life? Or: how might the cilium have been front-loaded? And so on).
Conclusion
We’re getting to the point where we can begin developing a rigorous design hypothesis in biology, and where we can make testable predictions about the world of life based on an ID model. In the first stages of formulating this ID hypothesis, we need a lot of imagination and folks who can think outside the box. And so let’s start proposing ID hypotheses that can be tested, and prove that ID does indeed offer testable hypotheses in biology.
About me
Over the years, I have become quite interested in the discussion over biological origins, and I think there is “something solid” behind the idea that teleology has played a role in the history of life on earth. When I’m not doing multiple sequence alignments, I’m thinking about ID and writing articles on the subject, which can be found on my website, The Genome’s Tale.
I am grateful to UD member kairosfocus for providing me with this opportunity to make a guest post on UD. Many thanks to kairosfocus.
Also see The Design Matrix, by Mike Gene.>>
_____________________
The above is of course quite interesting, and presents a particular hypothesis for design of life. Others are of course possible, but if we take front loading in (a) restricted [“island of function”] and (b) general [universal common descent] senses, we see that one may accept a and b, accept a but not b (or, b but not a!), or reject both a and b. So, it is a useful, flexible, testable hypothesis that underscores how “evolution” as such is not the opposite of design.
Let the unfettered observational evidence decide what is true!
The issue design theory takes is with a priori, Lewontinian evolutionary materialism dressed up in the holy lab coat and improperly inserted into the definition and methods of science under the label “methodological naturalism,” not with even the universal common descent of life forms from one or a cluster of unicellular ancestral forms. For instance, well-known ID researcher prof Michael Behe, accepts universal common descent.
I would add, that design theory has in it a great many other testable, and indeed well tested hypotheses, such as that:
1] irreducibly complex systems constrained by Mengue’s criteria C1 – C5, will be hard or impossible to come about by chance variation and blind natural selection,
2] complex specified information, especially functionally specific complex information, as can be expressed in the log-reduced form:
Chi_500 = Ip*S – 500,
bits beyond the Solar System threshold of complexity
. . . is an empirically reliable sign of origin by intelligently directed choice contingency, aka design,
3] The per aspect explanatory filter [as an explicit expansion and detailing of the classic “scientific method”] will reliably allow us to assign causes for observed aspects of phenomena, objects or processes, across chance, law-like mechanical necessity and design:
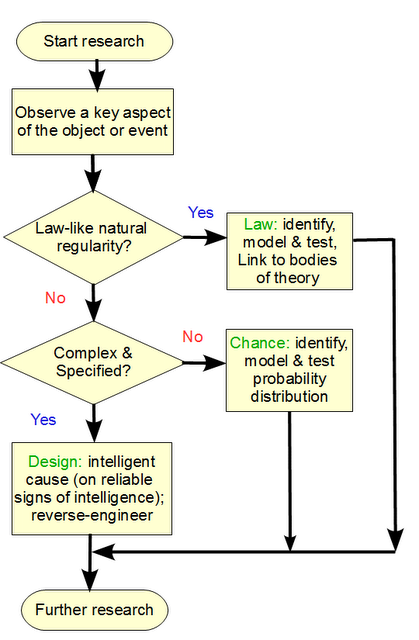
- The per aspect design inference explanatory filter
4] That cost of search compounded by search for a search etc, leads to a “no free informational lunch” consequence (once we are at a reasonable threshold of complexity, tied to the universal or restricted plausibility bounds as described by Abel).
5] That physicodynamically inert prescriptive information joined to implementing machinery etc, and sources of energy, materials and components, imposes a cybernetic cut or chasm not bridgeable by blind chance and necessity.
6] Etc, etc.
So, we are in a position to have a pretty useful onward discussion, thanks (again) to Genomicus. END
(Series on front-loading continues here)